AI Trend
Where are all the RAGs?
fore ai surveyed over 30 RAG developers on use cases and pain points. We present the results, which outline LLM trends and shed light on why adoption of LLM for RAGs has been slower than expected.

Over the past month, we have talked to more than 30 RAG builders in many different verticals from all over the world about their use cases and pain points. Here is what we learned.
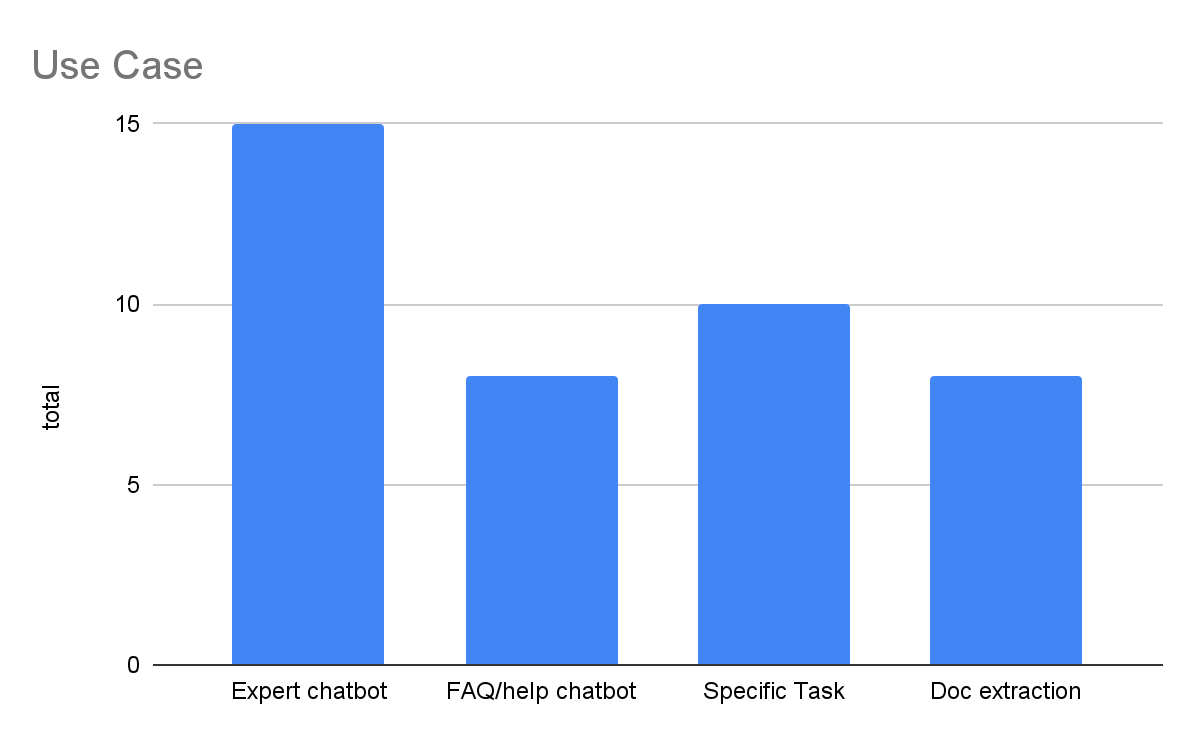
Main Use Cases: From Expert Chatbots to Document Extraction
As companies explore the potential of AI for their enterprises, they are focused on building RAGs (Retrieval-Augmented Generations) on top of their own data. The primary use cases include:
Expert Chatbots
Specialized chatbots designed to provide information on an expert domain, promising to make employees more efficient by expediting information-seeking tasks.Task-Specific Solutions
Using LLMs not as conversational UIs but to solve specific employee tasks, such as automatically distilling reports with a specific structure from multiple input sources.Document Information Extraction
Extracting structured information from documents.Website Chatbots
Providing high-level information sourced from a website for customers and visitors.
Pain Points: Retrieval and Chunking Hurt the Most, Hallucinations Less So
1. Retrieval and Chunking is Hard to Get Right
Developers frequently struggle to:
- Determine the right strategy for chunking data and adding metadata.
- Retrieve relevant chunks from queries.
Issues include:
- Relevant chunks being distant from the query in embeddings.
- Questions requiring reasoning across multiple chunks.
- Relevant context being cut off during chunking, leading to incorrect LLM answers.
Key Practices:
Successful developers create custom data-specific chunking algorithms and annotate chunks with extracted metadata. Over-retrieving and re-ranking are common strategies, while fine-tuning embeddings remains unexplored.
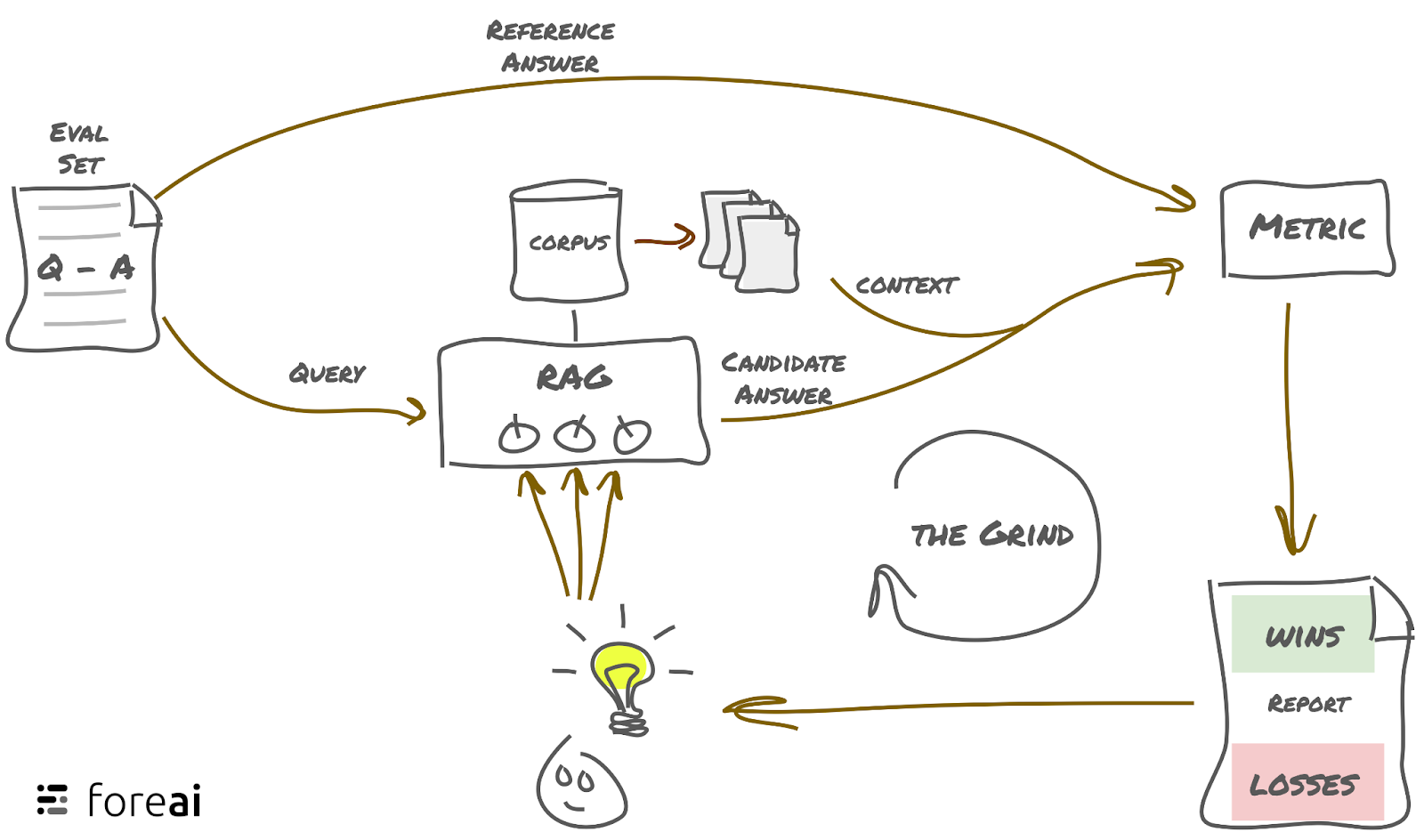
2. Streamlining Evaluations Will Save Time
- Developers manually evaluate RAG output for different configurations.
- Debugging errors manually using a few queries makes the process slow and error-prone.
- There’s a demand for tooling to systematically evaluate systems, enabling simultaneous experiments and informed quality improvements.
3. Input Parsing is Unsolved
- Many inputs are in formats like PDFs, tables, or infographics.
- Parsing and structuring such data for LLMs remains a significant challenge.
- Even simple tasks like extracting titles and sections for context augmentation are complex.
Current State:
While LLMs handle semi-structured outputs better than before, poor parsing can confuse generative processes.
4. Prompting is a Pain, But Not a Huge One
- Developers typically accept the challenges of prompting and focus on higher-impact tasks like retrieval and chunking.
- Initial prompts are rarely “gold-plated,” as addressing upstream issues often yields better quality improvements.
5. Hallucinations are Becoming Less of an Issue
- Larger, better-aligned models follow prompts more rigorously.
- When instructed to use context, they comply effectively.
So Where Are All the RAGs?
Out of the 30+ builders we talked to, only 2 have live RAGs in production. These companies invested significantly in engineering and quality work early on.
Status of Other Builders:
- Prototypes: Many are still in the exploration phase.
- Limited Testing: Some systems are being tested by a small group of users.
- Paused Projects: Others are paused due to unresolved trade-offs between quality, value, and cost.
Challenges:
- Stakeholders are cautious about launching AI systems that might risk embarrassing behavior over delivering meaningful value.
- Informational chatbots on websites have a lower quality bar compared to expert systems, which undergo more scrutiny.
Conclusion
While LLMs promise transformative capabilities, RAG adoption is slower than expected. Despite LLMs’ impressive abilities, significant work is needed to optimize:
- Chunking and Retrieval: Easier and more effective methods are critical.
- Input Parsing: The longstanding issue of processing unstructured data has gained new urgency with AI adoption on proprietary data.
The LLM is like a powerful motor, but its potential can only be unlocked by building a robust “car” around it.