Groundedness
How foresight could have saved Air Canada some troubles
Air Canada was recently ordered to pay compensation because of inaccurate information from their AI Chatbot. Here's how an LLM evaluation suite like foresight could have helped prevent this turbulence.

Air Canada’s chatbot recently made headlines because it gave incorrect information to a customer when they asked about their bereavement policy. The bot stated that the customer would be offered a discount and to apply for a refund after the flight. Well, that was incorrect. The request needed to be submitted before the flight. Air Canada refused to refund the customer. The customer should have gone to the link provided by the chatbot, where they would have seen the correct policy.
A tribunal rejected that argument and the airline had to refund the customer: “It should be obvious to Air Canada that it is responsible for all the information on its website.”
This situation serves as a cautionary tale for all organizations employing AI and automated systems:
- Impact on customer relationship: Any incorrect result can lead to a bad and frustrating customer experience.
- Reputational damage: The issues with providing incorrect information extend beyond just a single poor customer experience. As seen with Air Canada, such incidents can attract negative media attention, which can harm the company’s reputation on a larger scale.
- Legal and Financial Implications: The legal argument presented by Air Canada, suggesting that the chatbot was a “separate legal entity responsible for its own actions,” was rejected by the tribunal. It emphasizes the legal responsibility companies have for all information provided through their services, regardless of whether it’s delivered by a human or an AI.
Now what? Could this have been prevented?
You might wonder if it’s possible to catch such an error. After all, aren’t all LLMs prone to make mistakes, at least occasionally, and companies (and users) just have to live with them?
No, there are ways to detect structural issues with an LLM:
- During development: Systematic tuning of the system to prevent errors.
- Production-monitoring: Tracking the quality of the running system.
- Production-gating: Blocking of bad queries before they are shown to the user.
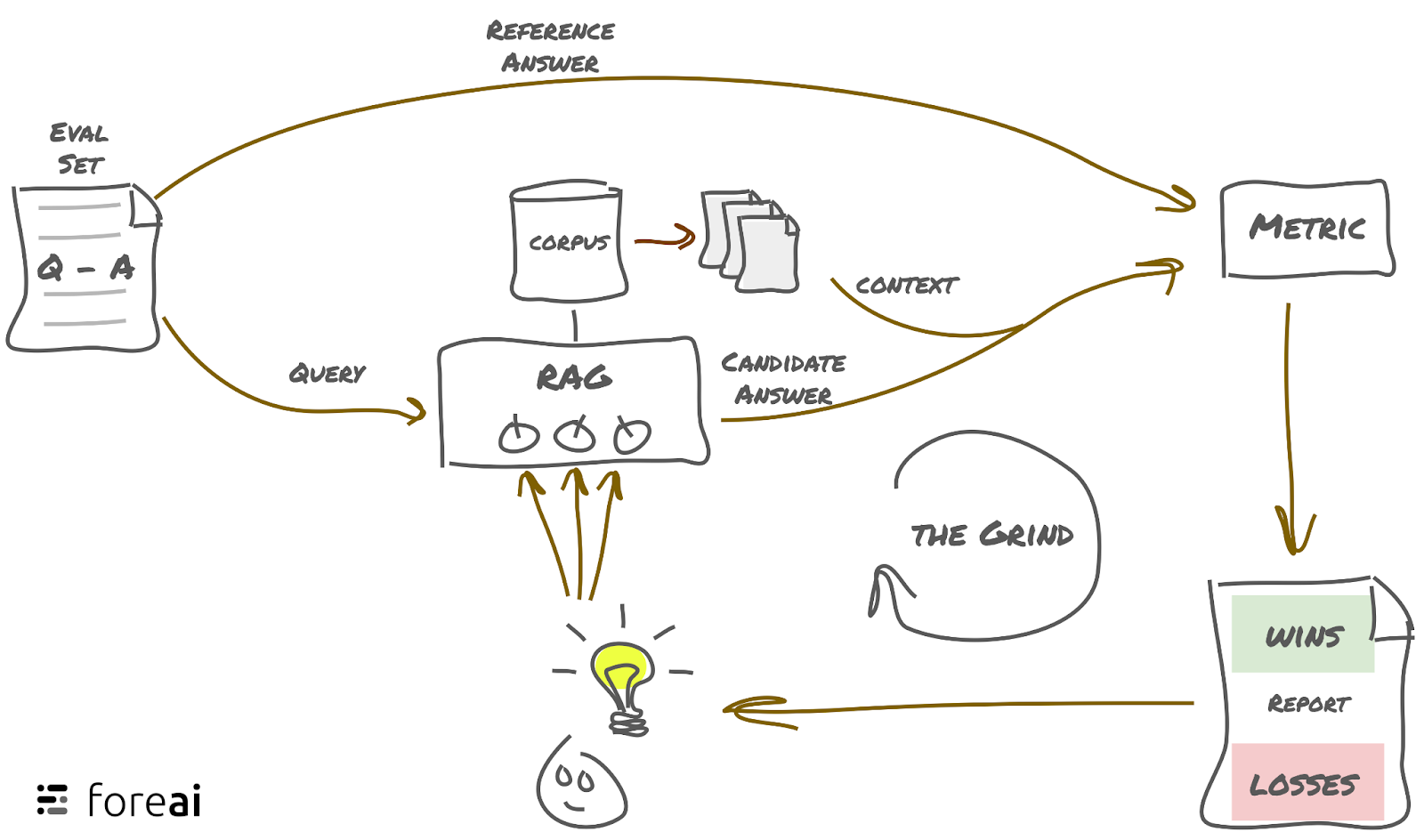
For either of these approaches, an accurate, systematic evaluation of the LLM’s quality is needed. Anecdotal trial and error will not be sufficient and will not catch such cases in a trustworthy way.
The fundamental issue in this example was that the chatbot gave an answer that was not grounded in the reference, the actual Air Canada policy . Air Canada stated the customer should have looked at the website instead, whereas the customer trusted the chatbot.
At fore.ai, we’ve developed a metric called ‘Groundedness’ This measures the extent to which an LLM fabricates answers and evaluates its accuracy. It is a key metric of our evaluation suite called “foresight.”
Groundedness: Is the response based on the context and nothing else?
We calculated our Groundedness metric for Air Canada’s chatbot reply. It turns out foresight would have flagged it as a pretty bad answer! Let us show you how.
The Air Canada example in foresight
We can actually calculate the groundedness score for this case. We do have everything we need:
- The context: The bereavement policy on Air Canada’s website.
- The question: We don’t have the exact question, but we can relatively safely assume that it must have been something like, “I am traveling for bereavement, can I get reduced rates?”
- The answer: chatbot gave (source)
“Air Canada offers reduced bereavement fares if you need to travel because of an imminent death or a death in your immediate family…If you need to travel immediately or have already travelled and would like to submit your ticket for a reduced bereavement rate, kindly do so within 90 days of the date your ticket was issued by completing our Ticket Refund Application form.”
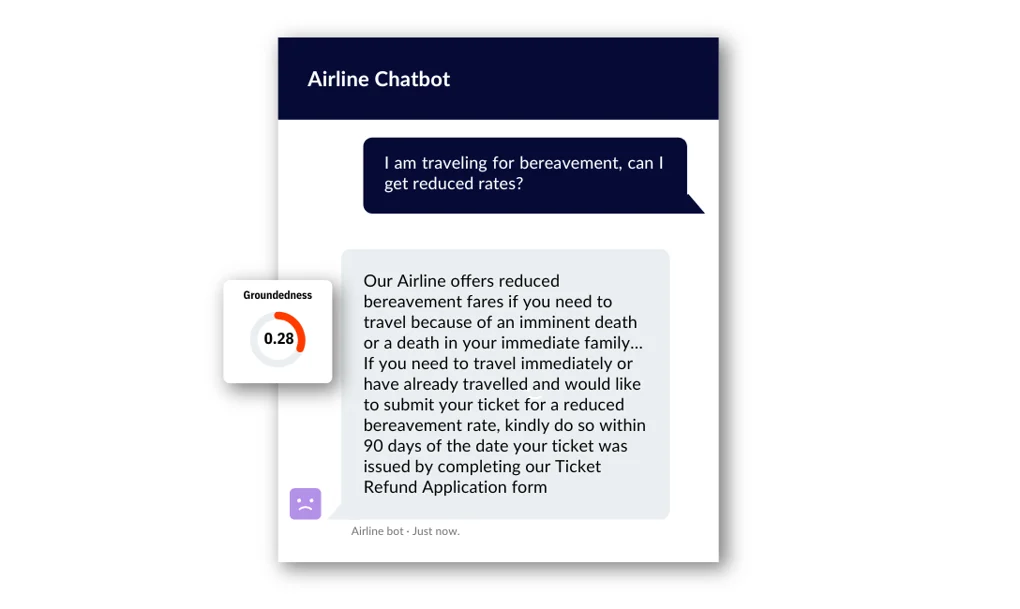
By inputting these three components into our ‘foresight’ LLM evaluation suite, we can assess the answer’s Groundedness and determine its score.
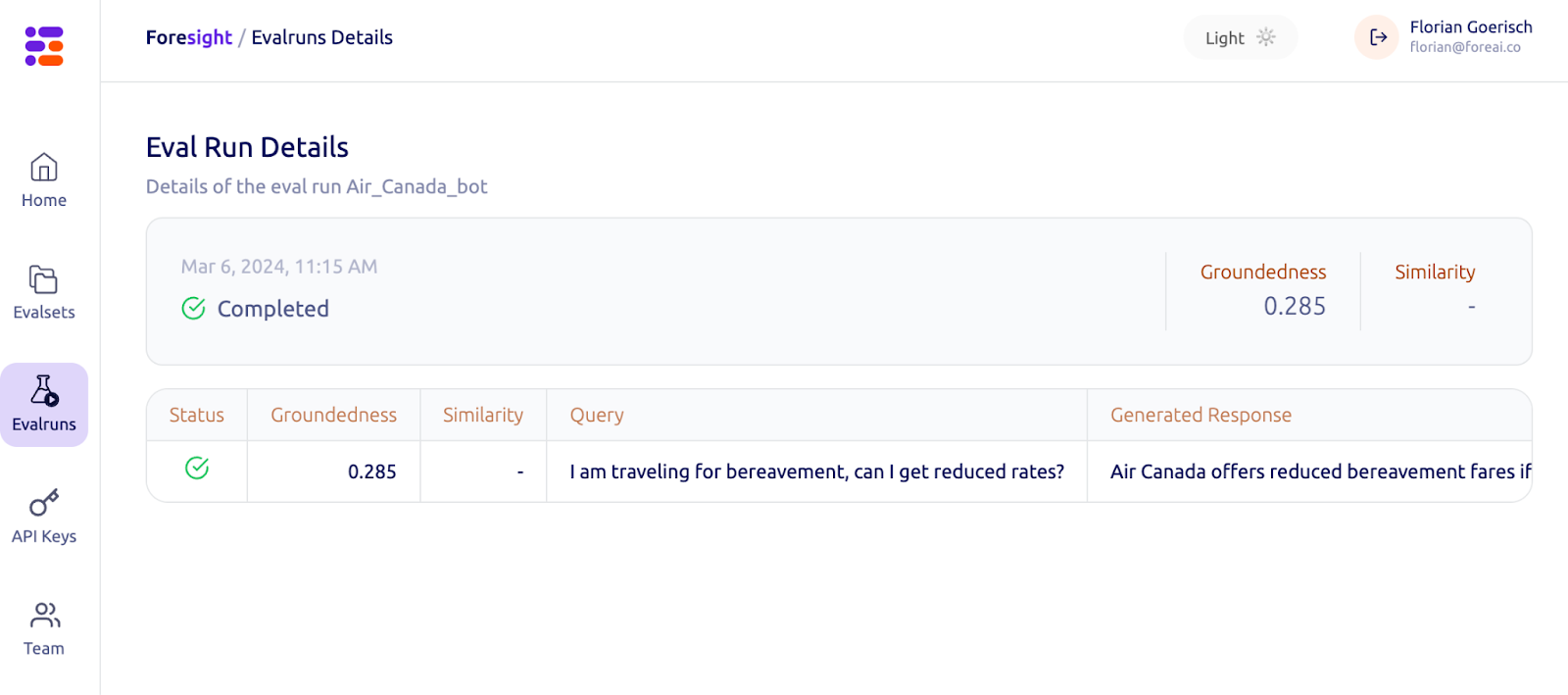
The result is a Groundedness score of 0.285 (in a range from 0-1). Let’s drill into this:
- If the answer had been based well on the context, the score would be much closer to 1. It is well below 0.5 and hence not grounded well.
- Why is it not 0? The answer is not completely made up! For example, the statement that Air Canada offers reduced bereavement fares is indeed true and part of the context.

Foresight allows users to drill into these details and understand which parts were grounded and which weren’t. You can see that the submission within 90 days has a low groundedness score of 0.09 because it is made up. Similarly, the completion of the ticket refund application is incorrect, as a phone call has to be made instead, and this form is not mentioned in the context.
How could this score have been used to prevent the incorrect answer?
Developers can utilize ‘foresight’ to identify and rectify inaccuracies in LLM-based applications during development and monitoring phases. They can either identify questions like this example beforehand and use them as ground truth or use log data to detect “bad” answers afterward.
These insights can then be used to iteratively improve the parameters of the LLM application (LLM model, embedding model, system prompts, RAG configuration) and hill climb towards a much better app.
In summary
Developers should avoid flying blind in the development of their LLM-based applications and use tools such as foresight to detect errors on a regular basis and improve their LLMs through these learnings.