AI Trend
The year of the AI quality hill-climb
Discover the potential and challenges of AI in 2024 as companies strive to improve accuracy and quality. Learn about the tools and strategies needed to climb the hill of AI advancement.

We are entering the second year since the widespread adoption of “AI.” At this point, almost everyone has experimented with ChatGPT and people are starting to rely on it more and more, gradually substituting it for Google in their quests for answers. Naturally, companies have become alert and are wondering about the potential this new capability will add to their business.
2023: The year of the AI demos
In the last year, many companies have thus started foraging for opportunities in their domain. Most companies don’t know yet how, but feel if they don’t explore and ride the wave, a competitor – or worse yet, a disruptor – will eat their lunch. Fuelled by FOMO, CEOs are breathing down the neck of their CIOs: Innovation budgets are repurposed, LLM hack-days organized, pizzas ordered and demos cranked out. Awesome examples are cherry-picked and circulated back up to the CEO with a sticky-note “it works”!
The “it works!” cases clearly demonstrate the huge potential of large language models. But not before long, the organization realizes that, to be actually useful, the AI solution needs to solve a real problem and provide value in the workflow itself. Therefore the quality of the output needs to increase, and by a large margin.
But AI needs love too
As generic as ChatGPT and other Large Language models are, unfortunately, there is no off-the-shelf solution that solves every AI use case. And it is incredibly hard to guarantee the reliability of an AI stack, as can be seen by recent examples. Building reliable AI solutions requires a lot of time. And I mean, a loooot of time. AI applications can not be ‘programmed’, like e.g. a Java program. Even if you have access to the weights of the model itself, which most application developers don’t have, you cannot simply command the system to do what you want it to. You have to ‘teach’ it, or ‘tell’ it in a prompt and hope it will understand. A large portion of the time in tuning the AI systems today is spent on ‘prompt-engineering’, a skill around which a new guild is rapidly forming. Unfortunately, the skill of prompt-engineering does not nicely generalize between models or follow any logical foundations: It’s mostly experience based, and not a transferable skill. Furthermore, there are a host of additional hyper-parameters that need to be tuned to optimize the system.
The skill-set required to progress on these tasks is different from the one of the classic software engineer: The path through this space is akin to finding an optimal solution in physics or biology. There are some weak signals here and there, some reasoning frameworks to go by and a lot of measuring and experimentation. It feels much more like research than engineering. At Google, there is a special breed of engineers that do this kind of work: “Quality Engineers”: Their job is to build tools, develop metrics, collect and annotate evaluation and training sets, and finally, write a little bit of code, run an experiment and check if it improves the metrics on their datasets, then iterate. Like in research: Measurements and experimentation are the central pieces in this whole process. The builders of AI systems need to exchange their imperative coding style mindsets and tools with metrics and evals and adapt to the new process.
2024: The year of the hill-climb
After having seen the potential of AI in the “It works!” demos, and realizing that there is a lot of work between the demo and the production system, we foresee that in 2024 companies are going to need to get started to climb that hill of AI accuracy. They should decide on their first use case, focus their resources and dedicate an engineering team to tackle the problem with determination. It will take more than a few hack-days. The process of hill-climbing accuracy can be arduous: It is an iterative process that requires deep analysis, perseverance, and love for the final product.
And it needs good tooling!
These are the essential elements needed to improve your AI system in a systematic manner
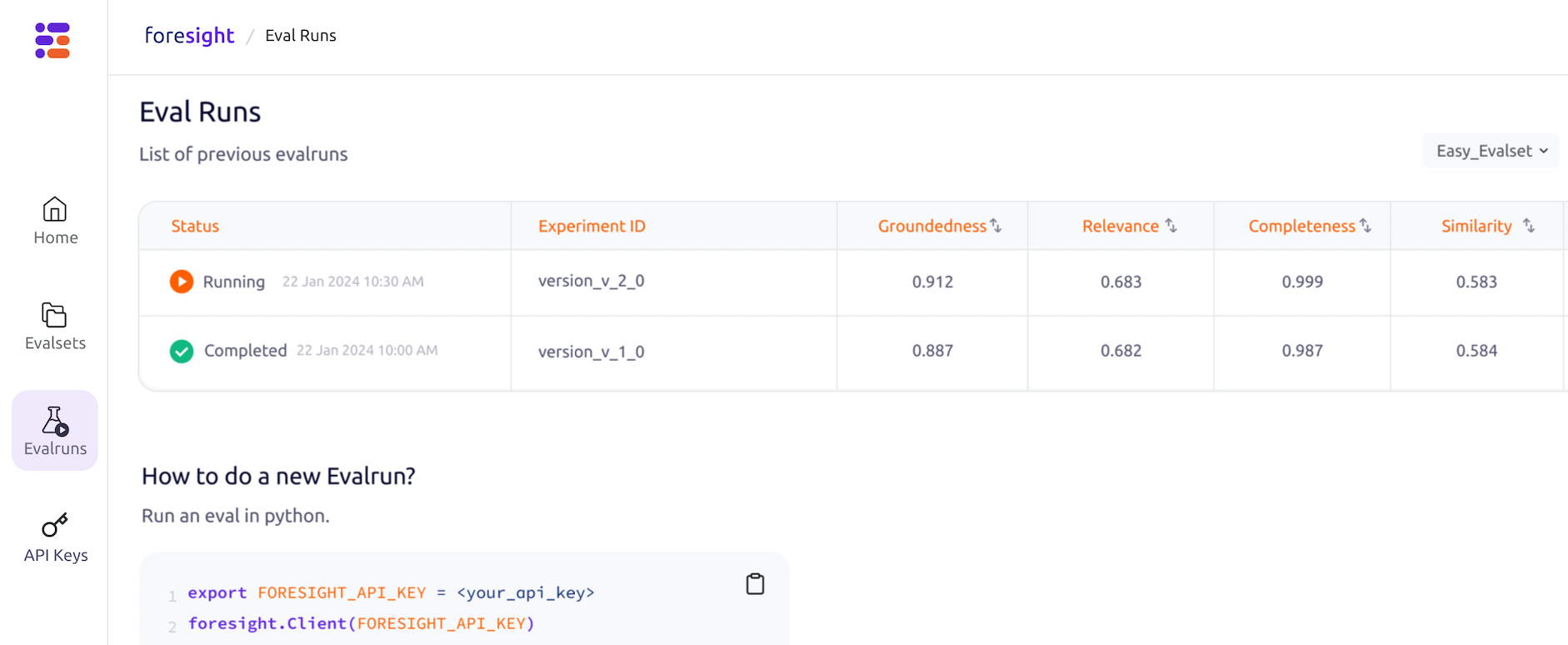
Evaluation Sets
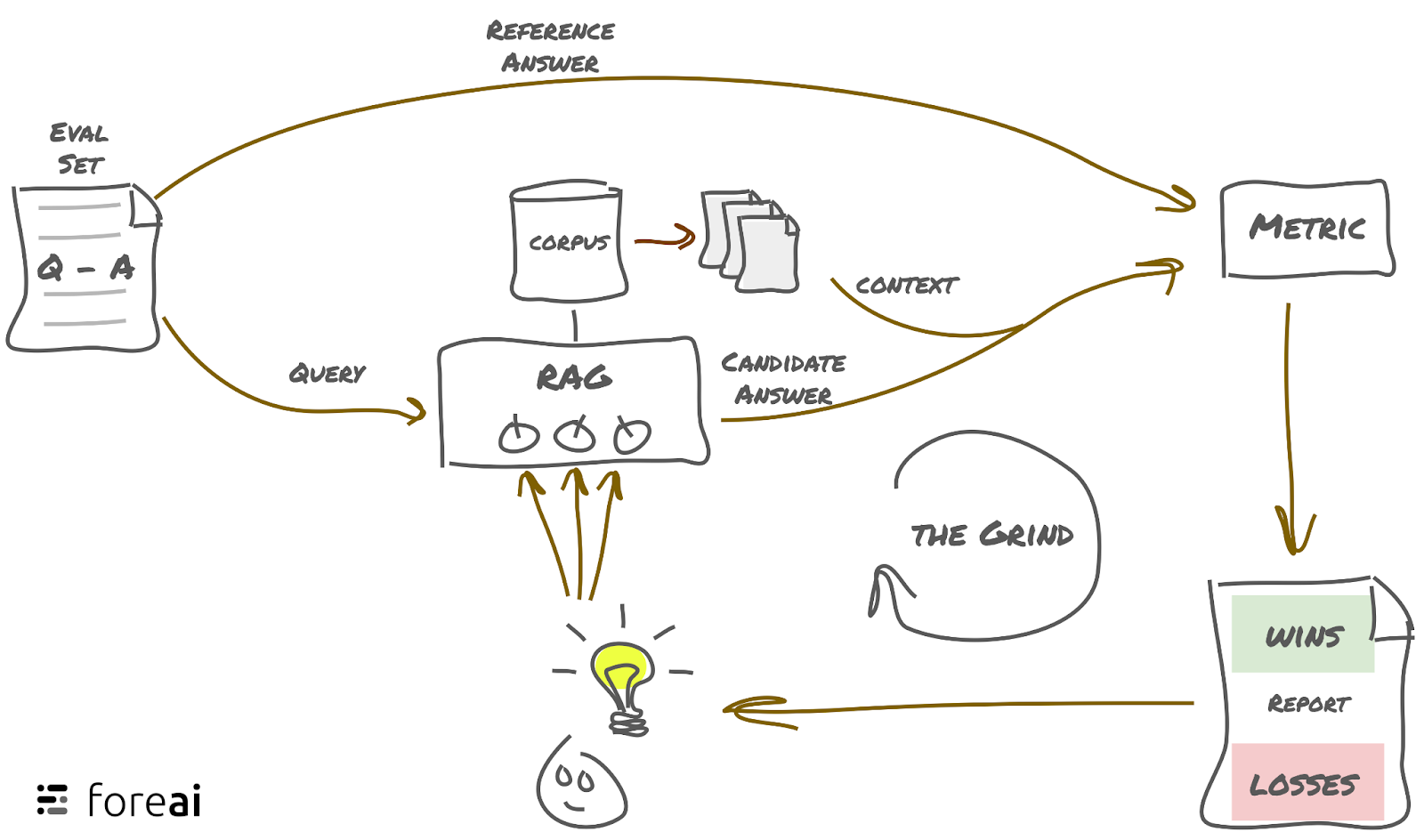
Evaluation sets are hand-tuned sets of examples of query / response pairs that demonstrate the ideal behavior of the system. Today, usually RAG or LLM application developers have their favorite set of a handful of queries that they anecdotally check. This is a dangerous whack-a-mole approach: while fixing one problem on one query, you may well be introducing a new problem on another query without noticing it. To systematically and deterministically improve a system, you will need a much larger evaluation set (or evalset). Collecting these evalsets is tedious work and requires close collaboration with the product owners. Inspiration should also be taken from actual usage logs. In a sense, if language is the medium, these evaluation sets define the product.
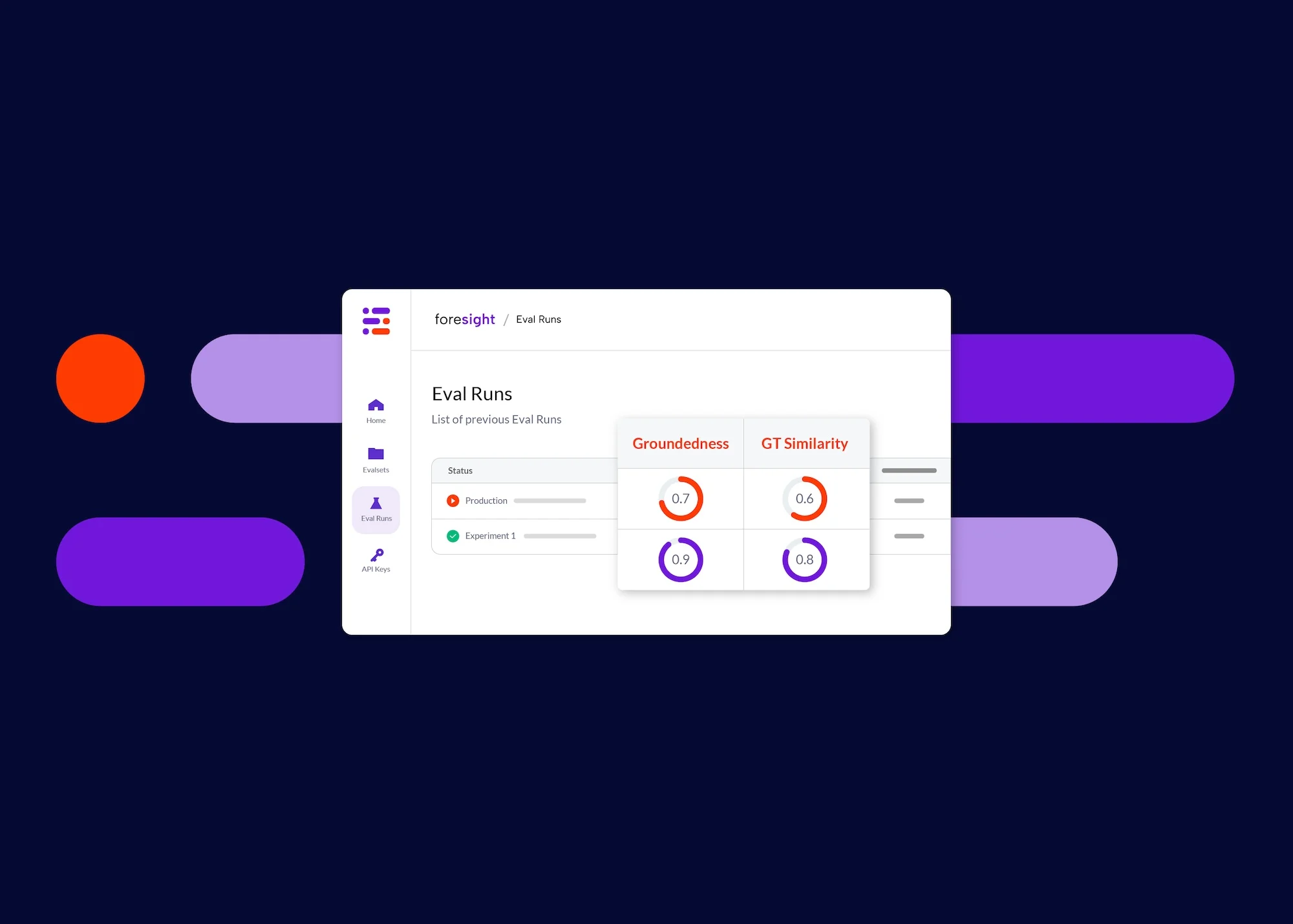
Metrics
For a provided response in the evalset, metrics measure how far away the system is from the optimal response. Today, after running their favorite queries, developers are manually inspecting the new outputs and intuitively judging which is better. This results in noisy signals and biased decisions. Furthermore, manually checking results takes a long time and results in slow development cycles. Given a metric and an evalset, developers can get almost immediate feedback or even run grid-searches on training sets to find the optimal configuration for their system.
Debugging and observability tools
Once the quality of an experiment has been assessed using the metrics and evalsets, we need tools to inspect the wins and losses and allow us to observe the internal workings of the system and answer questions like: Why does this particular query not perform well anymore? Why was this document retrieved? Why did it disregard this fact? Why is it providing the answer in German?
Maybe it’s a bug in the code, or maybe it’s an edge case we need to include, or maybe it’s a silly thresholding of a signal that, if adapted, will trigger another problem elsewhere. Getting to the bottom of this will inform the next set of actions to improve on quality.
You will see the sun on top of the hill!
If engineers engage in this hill-climb, great things will happen: as the evaluation metrics are winding their way up, the usage metrics will follow soon after!
Here at fore ai such a toolchain is in the making. We call it “foresight” and it will offer a set of initial metrics and the functionality to build and curate your evalsets and track your system’s performance over time.