Evaluation
Case Study: Building a RAG that knows about Cancer - What issues to expect
Building RAGs is fun, but even with AI, there is no free lunch: To get your system to high quality, work is required. We have outlined here some of the common problems that may occur, and how to detect and fix them.
I was recently invited by kaiko.ai to talk about the evaluation of large language models (LLMs) in the Oncology/Multimodal Applications track of AMLD 24 in Lausanne. In my talk, I followed the process of building a real Retrieval-Augmented Generation (RAG) system with information about cancer and outlined all the common problems—and how to fix them—throughout the process. Given the positive feedback from the audience, I decided to share the whole process with the readers of the fore ai blog.

When ChatGPT was released 1.5 years ago, the potential of large language models was immediately apparent to everyone. Despite its ease of use, we still don’t encounter many specialized LLM-based products in the wild.
Why Is That?
Building LLM Apps Is Easy
Modern LLMs are generic enough to answer specific questions when provided the right context and prompt, often without any fine-tuning. Developer tools like LlamaIndex and LangChain abstract away the complexities of training and hyperparameter tuning. Today, building an expert system for your own data can take as little as five lines of code:
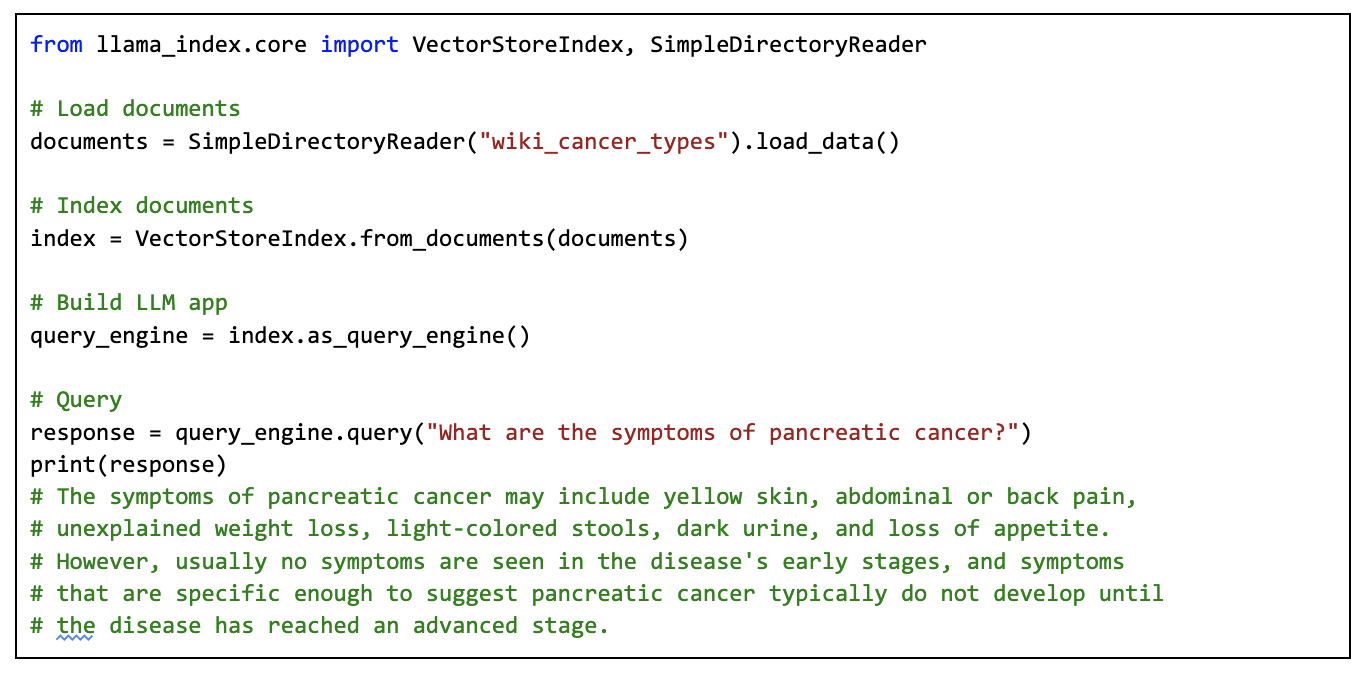
Building LLM Apps Is Also Hard
Behind the scenes, a RAG system is constructed:
- Documents are read from a directory.
- The documents are chunked and indexed using an embedding API.
- During inference, queries are embedded, documents are retrieved using a nearest-neighbor search, and the results are passed to the LLM API for generating the final answer.
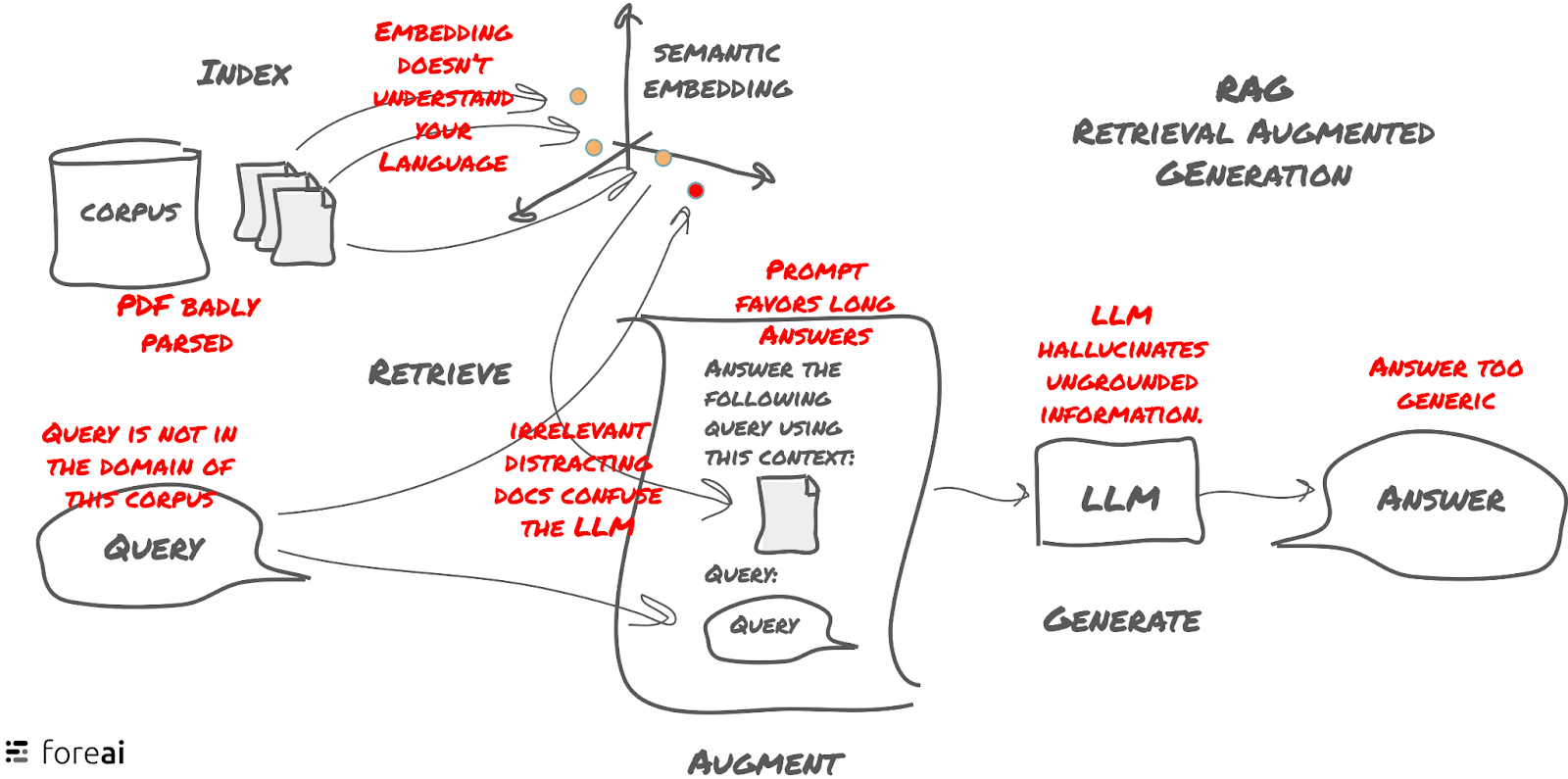
There’s a lot of complexity in this underlying layer, and lots of little things that can go wrong and pile up until the final answer is presented to the user. Unfortunately, the classic engineering toolchain with debuggers and testing fails to help in this process. New tools are needed, I will describe what they look like in this post.
Case Study: A RAG That Knows About Cancer
To demonstrate one potential application of LLMs in oncology, I built a RAG system using basic information about cancer types, symptoms, and risk factors. This was not intended for medical purposes but as a quick proof of concept to illustrate how easy—and challenging—it can be to build a high-quality RAG.
I scraped Wikipedia’s List of Cancer Types and Category: Cancer pages and loaded the documents into a RAG. The results were impressive overall but highlighted some key challenges:
Example: Instabilities from Questions
Small changes in the query can yield significantly different responses.


For instance:
- Adding a question mark at the end of a query changed the LLM’s confidence in the data.
- Rephrasing a statement slightly altered its perceived accuracy.
Those diagnosed vs those who survive one year after diagnosis is a much worse loss as we shall see below.
Example: Anecdotal Retrieval
Semantically equivalent queries may lead slightly different embeddings, which in turn, can lead to a different set of documents that are retrieved. We call this ‘Anecdotal Retrieval’, docs are retrieved like a few random anecdotes, rather than comprehensively. As a consequence, the LLM does not have access to all relevant documents, but will emit a response with high confidence nonetheless:

In this example, two different sets of docs (though with a large overlap) are retrieved from the two semantically equivalent queries. This in turn, causes the LLM to reply with a different response: ‘Ovarian cancer’ is omitted from the second response.
Example: Takin’ it easy with the nuances
Nuances can be quite important, and a small reformulation can lead to a semantically very different meaning. Let’s revisit the example from above:

The baseline for the 12% is ‘diagnosed’, and not ‘have survived one year after diagnosis’, hence the survival rate for those who survive one year after diagnosis is more like 50%. This sort of error is really bad and needs to be detected and handled.
So how do we fix it?
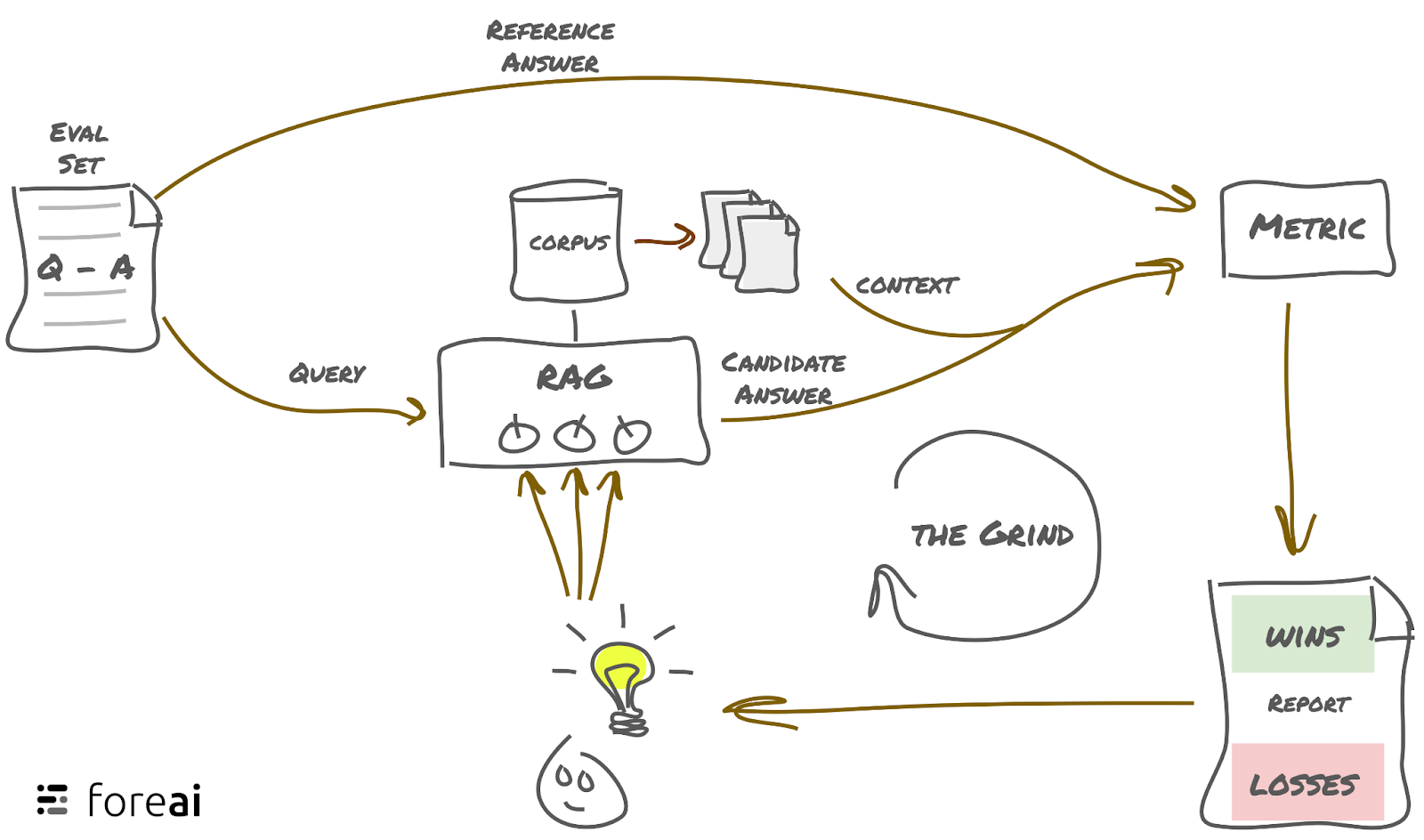
A RAG or any other LLM app has many hyper parameters which can be tweaked (The knobs in the RAG box above): Chunk size, embedding model, ranker, prompt, …. There is usually no explicit way to find the optimal parameters, so these need to be found iteratively, similar to how the weights are determined via gradient descent in the underlying models.
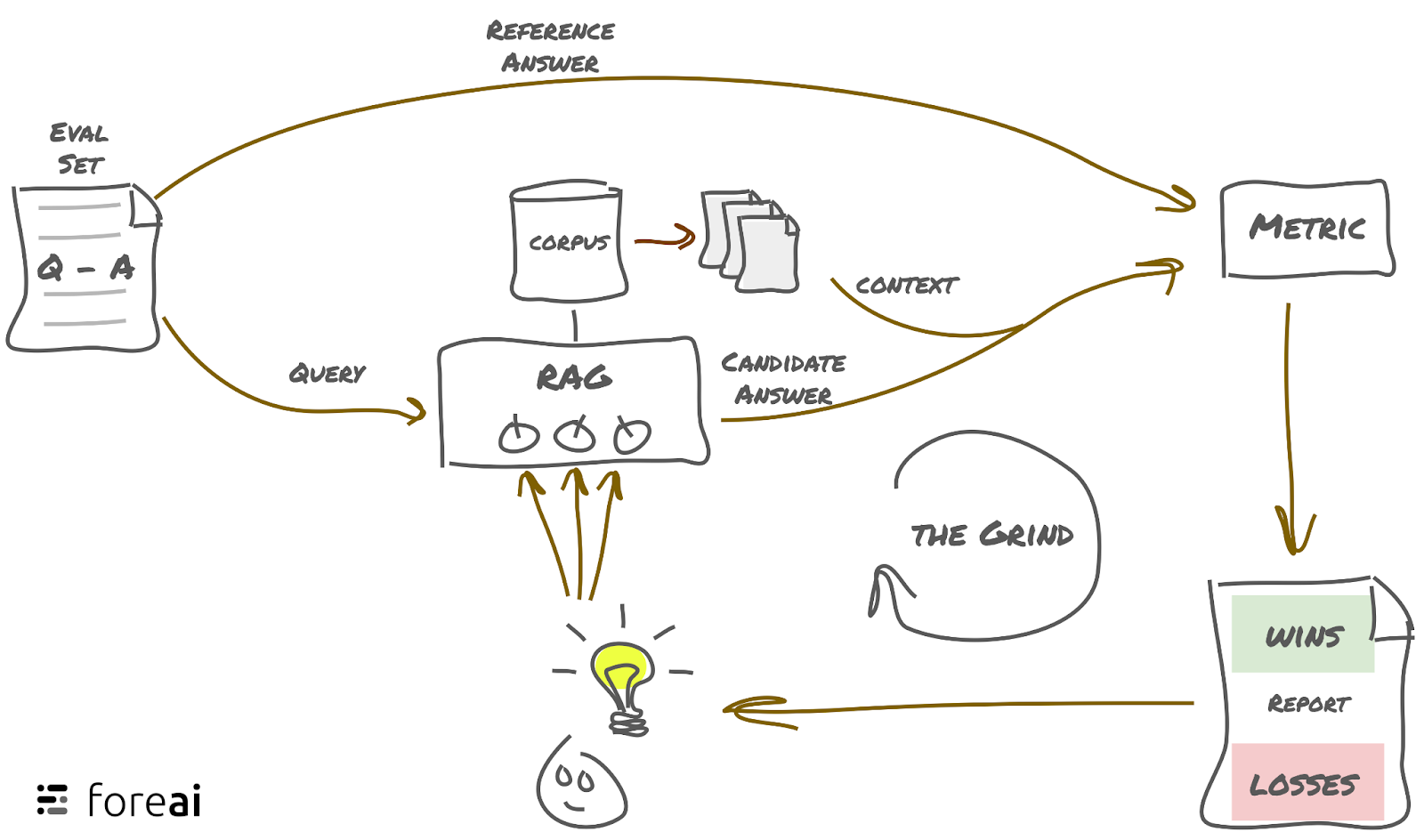
The process is roughly:
- Build an evaluation set
- Run an evaluation of your RAG
- Compute scores for the output of your RAG
- Look at worst offenders and determine the headroom
- Implement a fix for your headroom and tweak your parameters
- Iterate: Go to step 2
Build an Eval Set
Your eval set is a set of questions and their associated ground truth answers (sometimes questions alone suffice as well). This is the most important thing, and you should be prepared to spend some time on this because this will define the final quality of your LLM app.
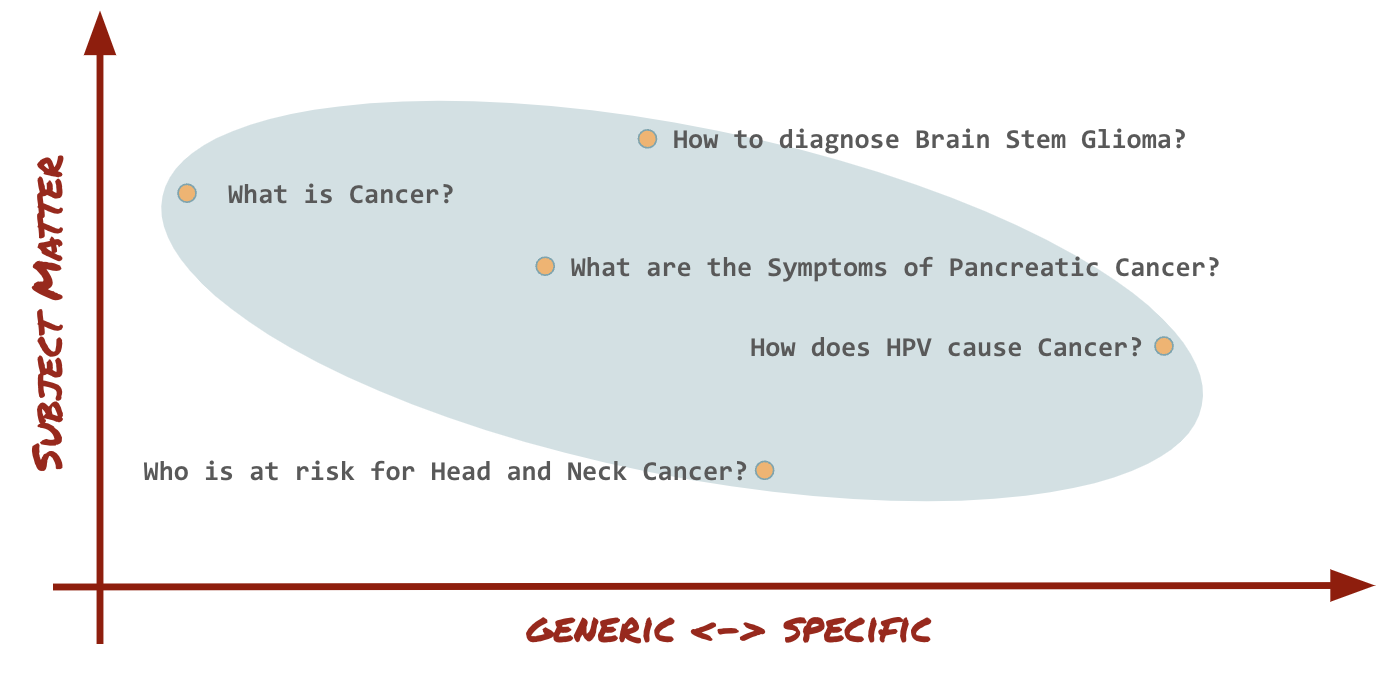
Make sure the eval set covers the whole scope of your product. This means, for example, it should contain generic as well as detailed questions and probe questions in different parts of your corpus. Remember: you only have eyes on your system where your eval set is. Ideally, such a set would include upwards of 100 question-answer pairs.
It can be quite tedious to create these eval sets, so there are some tricks to bootstrap your set:
- You can let GPT-4 or any other large model create a question-answer set automatically from your corpus.
- If your system is live already, you can sample your set from live traffic. This is most useful because it 100% reflects the usage of your product. It has the downside that it doesn’t contain ground truth answers though.
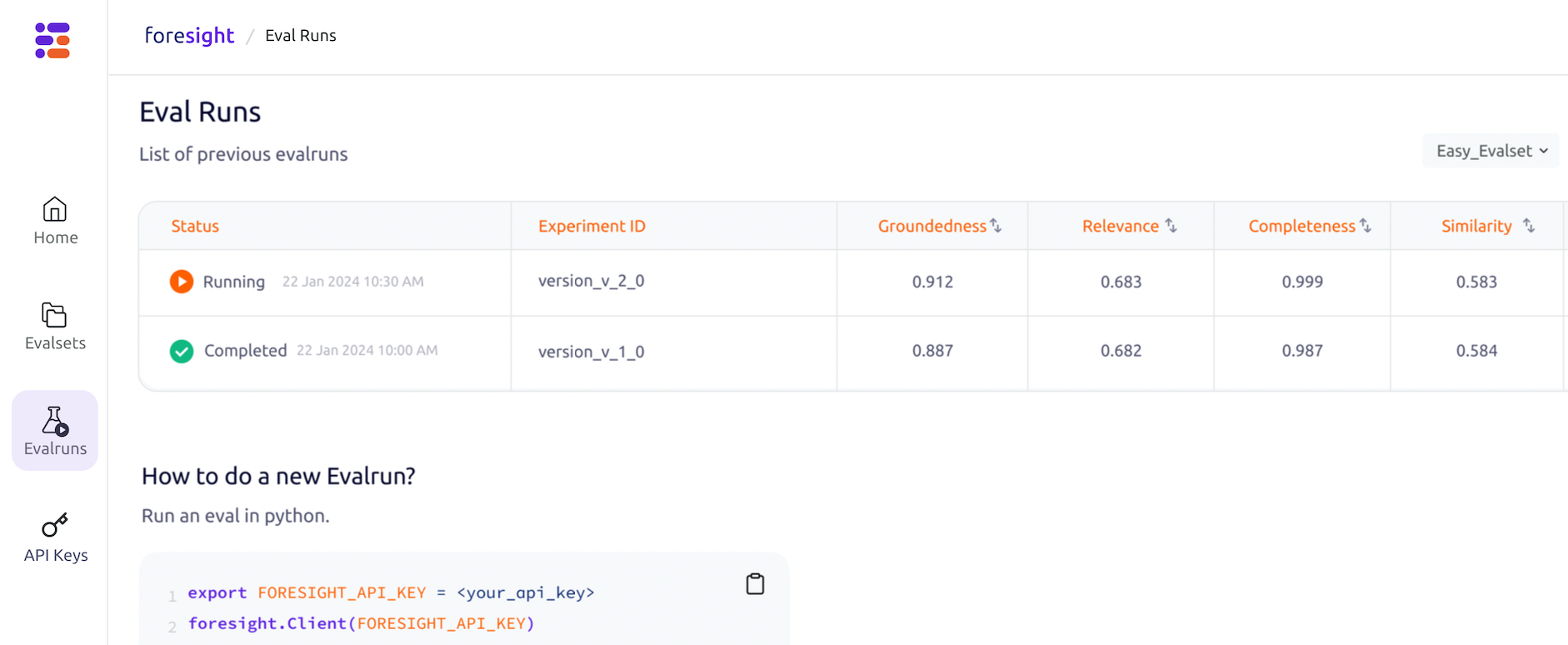
Run an Evaluation and Compute Metrics for Your RAG
In the next step, the RAG is run against the eval set, and every candidate answer from the set is compared to the reference answer or checked against other metrics. Here’s a list of metrics that are useful:

For example, Groundedness checks whether the answer is based on the corpus and the corpus alone.
Here it is at work:
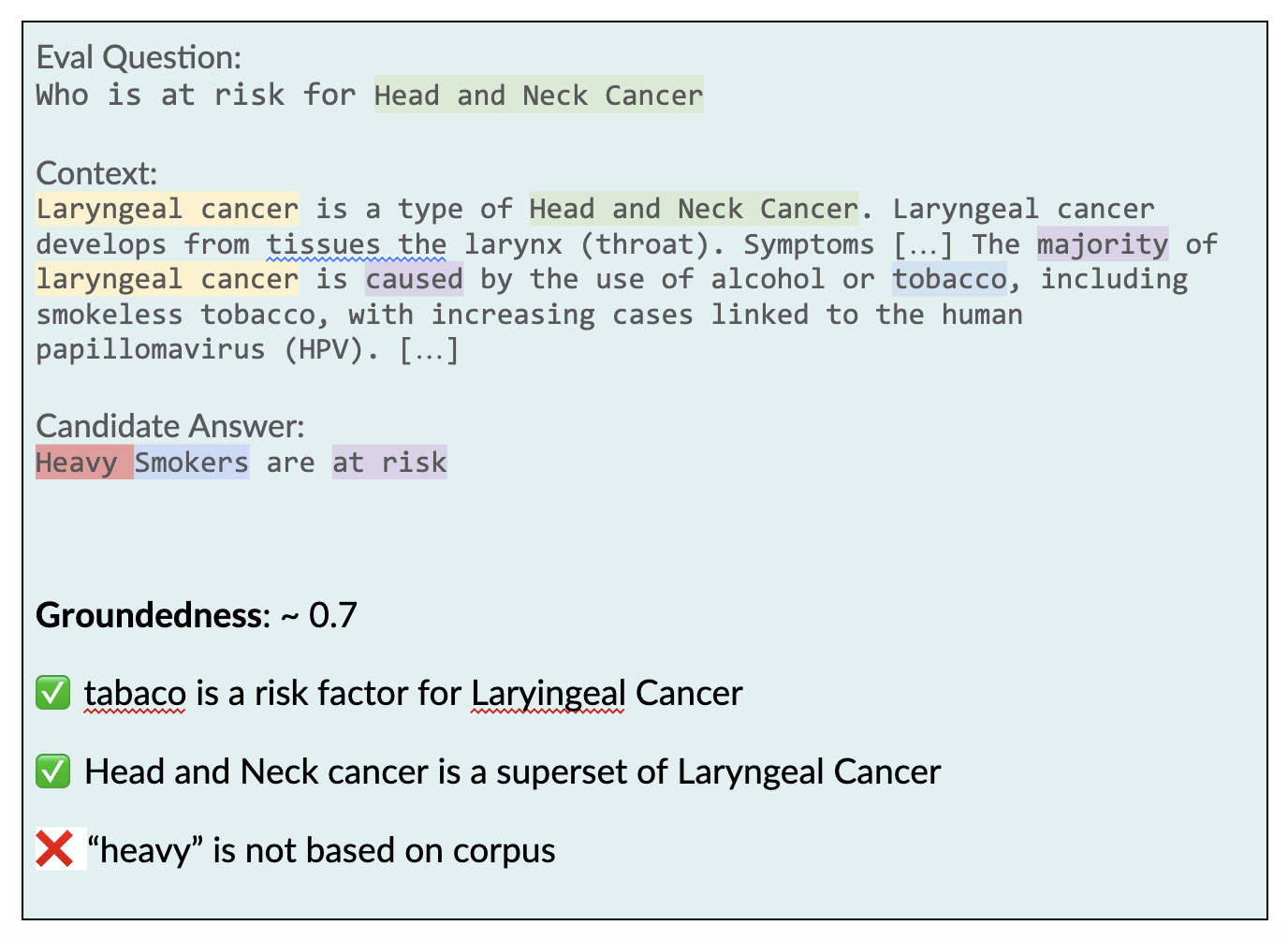
In this example, the context does not contain any information about the risk factors of Head and Neck cancer directly, but it talks about the risk factors for the more specific type of Laryngeal cancer. Since it contains the fact that Laryngeal cancer is a subtype of Head and Neck cancer, the risk factors listed for the former are also risk factors for the latter. Hence, the metric attributes a high score for groundedness to these risk factors because they are entailed in the context. Conversely, the context does not talk about heavy smoking, which may be intuitively correct, but since it is not mentioned in the corpus, it will get a low score.
Find the Headroom and Tweak Your System
Once we have a report of all Question-Answer pairs and their corresponding scores for the metrics we care about, we can sort them by scores and look at the top-performing and worst-offending queries. The main idea here is to find clusters of systematic issues, rather than edge cases. Such a systematic issue could, for example, be:
- Most queries in Spanish are broken because irrelevant documents are retrieved.
- Many responses include additional practical information that is not explicitly mentioned in the corpus.
- Some responses are answering with irrelevant information.
From each of these issues, you can derive a hypothesis about what is causing it and tweak your system to mitigate the problem. For example:
- Broken Spanish queries because of retrieval: Your embedding is not multi-lingual.
- Additional non-grounded information in the answer: Prompt is not authoritarian enough about only using the provided context for the response.
- Irrelevant information in the output: Too many non-relevant documents retrieved. Improve embedding or retrieve fewer documents.
Today, these metrics are implemented using LLMs themselves or specialized smaller models.
Iterate
Once you have your fixed candidate, run a new eval and watch your metrics go up and to the right!
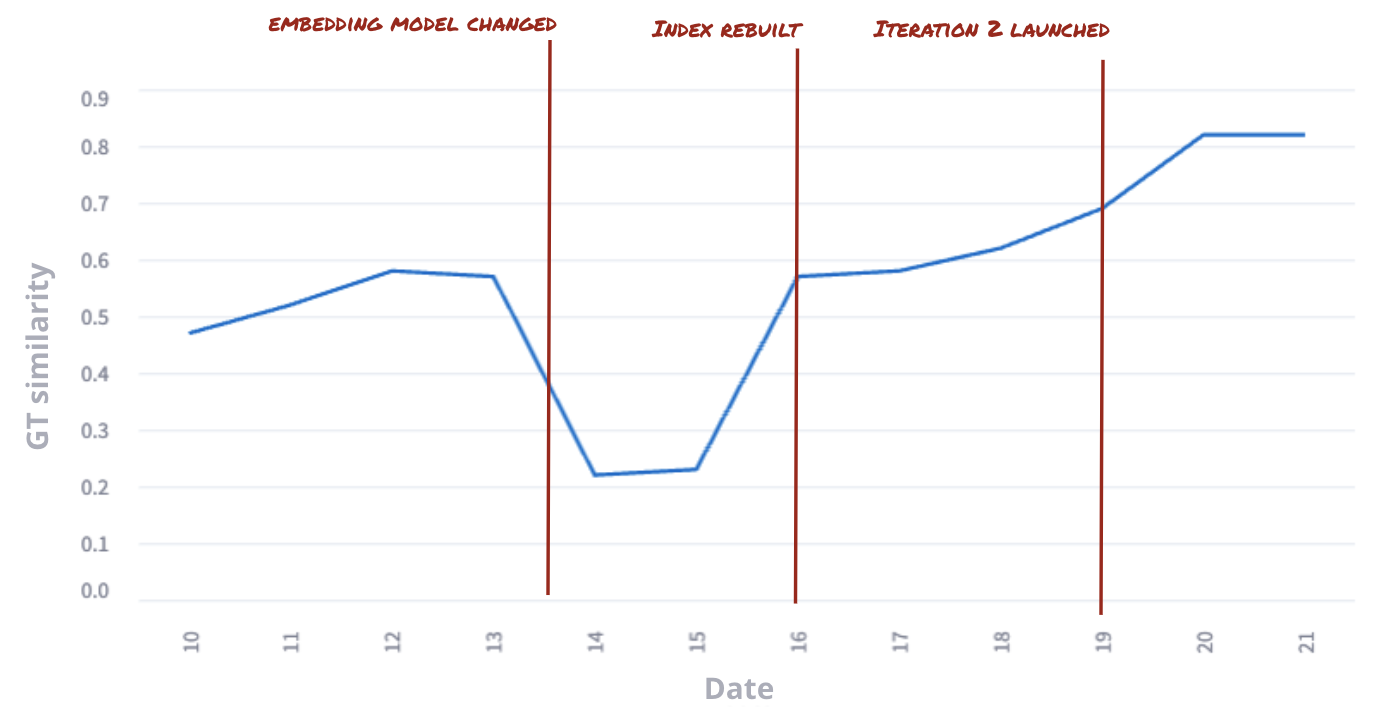
It is advisable to continuously run metrics on your live traffic. Many things may happen over time, like:
- Your embedding provider changes the underlying model and your index doesn’t match anymore.
- Your query mix changes.
If you run metrics daily, you will notice issues very quickly!
Conclusion
Building RAGs is fun, but even with AI, there is no free lunch: To get your system to high quality, work is required. We have outlined here some of the common problems that may occur and how to detect and fix them.
We are building a toolsuite to help you with all of the above steps. Please sign up for beta testing on foreai.co.