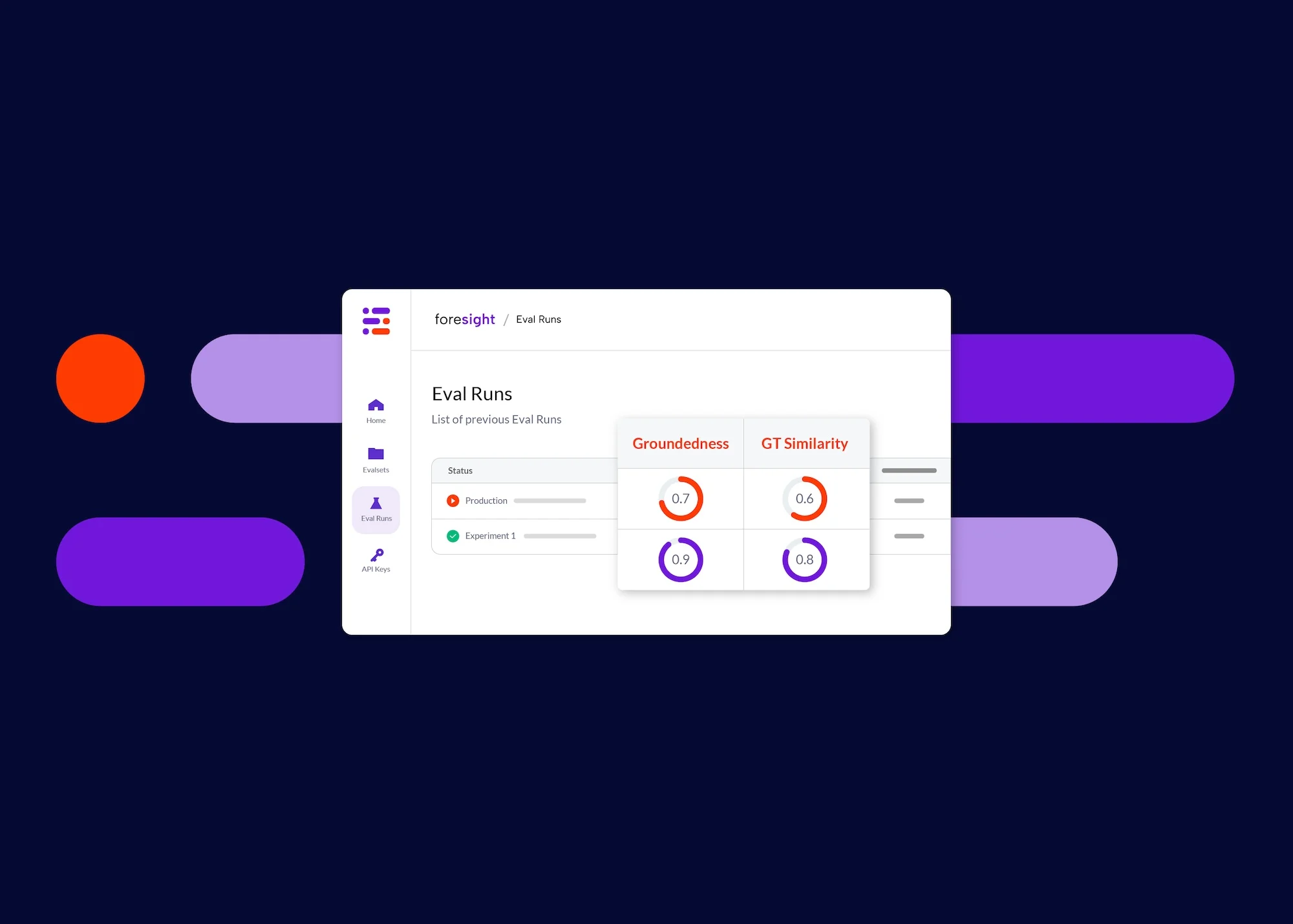
GT Similarity
Evaluation is all you need: metrics for evaluating Language Model applications
Explore the importance of evaluating Language Model applications through metrics like Groundedness and Ground Truth Similarity. Learn how these metrics enhance LLM performance assessment.
In the ever-evolving landscape of natural language processing, the significance of evaluating language model applications cannot be overstated. As the demand for more sophisticated and context-aware applications rises, it becomes crucial to employ metrics that can help evaluate these language model applications at scale. We covered the need for such approaches in a previous post by our CEO, Fabian. In this post, we cover some of the metrics that fore ai has been working on to provide a more comprehensive understanding of LLM application performance. Among these metrics, Groundedness and Ground Truth Similarity stand out as the first to be released through our flagship product, foresight.
Let’s dig deeper into what these metrics offer through some example cases.
1. Groundedness
Case study: Summarization
Groundedness is a metric that addresses the model’s ability to connect language with the real world. In essence, it measures how well an LLM-based application understands and incorporates context into its responses. A grounded language model not only generates coherent text but also demonstrates an awareness of the broader context and the nuances of the topic at hand.
This is one of the most important metrics required to evaluate an LLM system, as these models are prone to hallucinations. This has also been ratified as one of the top developer pain points through recent developer surveys.
As a case study, we provided a slide deck about our tool, foresight, to three RAG (Retrieval-Augmented Generation) systems built with different configurations and asked them to summarize the content using the same prompt. And here are the results:
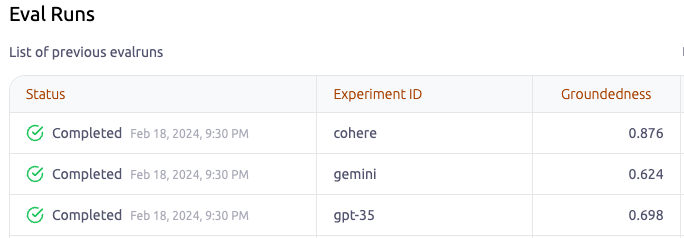
It wouldn’t make too much sense to analyze the average scores here, since there was one prompt and one example used, but let’s look at a win and a loss of this example.
Win:

Please be aware that a score of 0.85 in this case is considered quite a high score. For responses with a high degree of factual accuracy, the score tends to be close to 1, but it will never be precisely 1 due to the probabilistic nature of the scoring system.
Loss:

Note how the model in this case misrepresents an LLM as a Language Learning Model instead of accurately calling it a Large Language Model.
Such nuanced errors are hard to catch for a human, but extensive debugging made possible through foresight allows one to go deeper into the reasons for getting lower/higher scores.

2. Ground Truth Similarity (GT Similarity)
Case study: Q&A
Ground Truth Similarity, another crucial metric, focuses on the AI system’s ability to produce text closely aligned with reference responses. This metric evaluates how well a language model captures the nuances of reference texts, involving a comparison of generated text with human-written ground-truth examples or a reference dataset to quantify semantic equivalence. It is useful for evaluating a range of use cases, but proves especially useful for evaluating Q&A use cases.
To exemplify Similarity, we created a RAG ingested with news articles from January 2024. We formulated a quiz with 50 questions, each having reference answers, and evaluated the RAG using foresight. The results highlighted cases where the RAG performed exceptionally well and instances where improvements were needed, emphasizing the utility of the Similarity metric in evaluating such use cases.
- A perfect response Ground Truth Similarity score: 0.997

- A very good response Ground Truth Similarity score: 0.734

- A bad response Ground Truth Similarity score: 0.003

⚠️ Note how in the last case the reference answer didn’t say anything about the attitude of the players or about how they might suffer another drubbing.
There might be a wide range of reasons why Similarity metrics may be low for a RAG. In the case highlighted above, some context was missing and hence the answer was bad. So in this case, fixing retrieval would help improve Similarity.
A Comprehensive Suite in the Making
In conclusion, Groundedness and Ground Truth Similarity mark the initial steps in developing a comprehensive suite of metrics for evaluating LLM application performance. foresight’s ability to provide detailed insights and facilitate metric debugging empowers developers to enhance the accuracy of their LLM applications.
As we continue to refine and release additional metrics, our goal is to provide LLM application developers with a robust toolkit for assessing LLM applications while they hill-climb on quality. If you are interested in being early users of foresight, please reach out to us.